引擎配置¶
Engine 是任何 SQLAlchemy 应用程序的起点。它是实际数据库及其 DBAPI 的 “基地”,通过连接池和 Dialect 传递给 SQLAlchemy 应用程序,Dialect 描述了如何与特定类型的数据库/DBAPI 组合进行通信。
通用结构可以示例如下
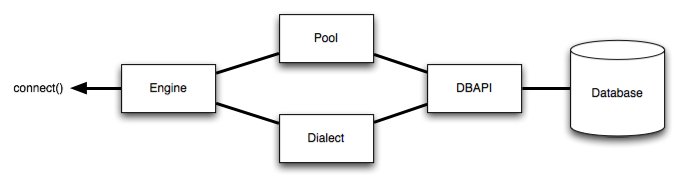
上面,Engine 同时引用 Dialect 和 Pool,它们共同解释 DBAPI 的模块功能以及数据库的行为。
创建引擎只是发出一个简单的调用,create_engine()
from sqlalchemy import create_engine
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost:5432/mydatabase")上面的引擎创建了一个针对 PostgreSQL 定制的 Dialect 对象,以及一个 Pool 对象,该对象将在首次收到连接请求时在 localhost:5432 建立 DBAPI 连接。请注意,Engine 及其底层 Pool 在调用 Engine.connect() 或 Engine.begin() 方法之前,不会 建立第一个实际的 DBAPI 连接。ORM Session 对象等其他 SQLAlchemy Engine 依赖对象在首次需要数据库连接时也可能调用这些方法中的任何一种。通过这种方式,可以说 Engine 和 Pool 具有延迟初始化行为。
Engine 一旦创建,可以直接用于与数据库交互,也可以传递给 Session 对象以使用 ORM。本节介绍配置 Engine 的详细信息。下一节 使用引擎和连接 将详细介绍 Engine 和类似对象的用法 API,通常用于非 ORM 应用程序。
支持的数据库¶
SQLAlchemy 包含许多用于各种后端的 Dialect 实现。最常见数据库的 Dialect 包含在 SQLAlchemy 中;少数其他数据库的 Dialect 需要额外安装单独的 dialect。
有关可用各种后端的信息,请参阅 Dialect 部分。
数据库 URL¶
create_engine() 函数基于 URL 生成 Engine 对象。URL 的格式通常遵循 RFC-1738,但有一些例外,包括在 “scheme” 部分中接受下划线而不是破折号或句点。URL 通常包括用户名、密码、主机名、数据库名字段,以及用于额外配置的可选关键字参数。在某些情况下,接受文件路径,而在其他情况下,“数据源名称” 替换 “host” 和 “database” 部分。数据库 URL 的典型形式是
dialect+driver://username:password@host:port/databaseDialect 名称包括 SQLAlchemy dialect 的标识名称,例如 sqlite、mysql、postgresql、oracle 或 mssql。drivername 是 DBAPI 的名称,用于使用全小写字母连接到数据库。如果未指定,则将导入 “默认” DBAPI(如果可用) - 此默认通常是该后端最广为人知的驱动程序。
转义密码中诸如 @ 符号之类的特殊字符¶
当构造完整的 URL 字符串以传递给 create_engine() 时,用户和密码中可能使用的特殊字符需要进行 URL 编码才能正确解析。。这包括 @ 符号。
以下是一个 URL 示例,其中包含密码 "kx@jj5/g",其中 “at” 符号和斜杠字符分别表示为 %40 和 %2F
postgresql+pg8000://dbuser:kx%40jj5%2Fg@pghost10/appdb可以使用 urllib.parse 生成上述密码的编码
>>> import urllib.parse
>>> urllib.parse.quote_plus("kx@jj5/g")
'kx%40jj5%2Fg'然后可以将 URL 作为字符串传递给 create_engine()
from sqlalchemy import create_engine
engine = create_engine("postgresql+pg8000://dbuser:kx%40jj5%2Fg@pghost10/appdb")作为转义特殊字符以创建完整 URL 字符串的替代方法,传递给 create_engine() 的对象可以是 URL 对象的实例,它绕过了解析阶段,并且可以直接容纳未转义的字符串。有关示例,请参见下一节。
在版本 1.4 中更改: 修复了对主机名和数据库名称中 @ 符号的支持。作为此修复的副作用,密码中的 @ 符号必须转义。
以编程方式创建 URL¶
传递给 create_engine() 的值可以是 URL 的实例,而不是纯字符串,这绕过了使用字符串解析的需要,因此不需要提供转义的 URL 字符串。
URL 对象是使用 URL.create() 构造函数方法创建的,分别传递所有字段。密码等中的特殊字符可以无需任何修改地传递
from sqlalchemy import URL
url_object = URL.create(
"postgresql+pg8000",
username="dbuser",
password="kx@jj5/g", # plain (unescaped) text
host="pghost10",
database="appdb",
)然后可以将构造的 URL 对象直接传递给 create_engine(),以代替字符串参数
from sqlalchemy import create_engine
engine = create_engine(url_object)后端特定的 URL¶
以下是常见连接样式的示例。有关所有包含的 dialect 的详细信息以及第三方 dialect 的链接的完整索引,请参阅 Dialect。
PostgreSQL¶
PostgreSQL dialect 使用 psycopg2 作为默认 DBAPI。其他 PostgreSQL DBAPI 包括 pg8000 和 asyncpg
# default
engine = create_engine("postgresql://scott:tiger@localhost/mydatabase")
# psycopg2
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/mydatabase")
# pg8000
engine = create_engine("postgresql+pg8000://scott:tiger@localhost/mydatabase")有关连接到 PostgreSQL 的更多说明,请访问 PostgreSQL。
MySQL¶
MySQL dialect 使用 mysqlclient 作为默认 DBAPI。还有其他可用的 MySQL DBAPI,包括 PyMySQL
# default
engine = create_engine("mysql://scott:tiger@localhost/foo")
# mysqlclient (a maintained fork of MySQL-Python)
engine = create_engine("mysql+mysqldb://scott:tiger@localhost/foo")
# PyMySQL
engine = create_engine("mysql+pymysql://scott:tiger@localhost/foo")有关连接到 MySQL 的更多说明,请访问 MySQL 和 MariaDB。
Oracle¶
首选的 Oracle 数据库 dialect 使用 python-oracledb 驱动程序作为 DBAPI
engine = create_engine(
"oracle+oracledb://scott:tiger@127.0.0.1:1521/?service_name=freepdb1"
)
engine = create_engine("oracle+oracledb://scott:tiger@tnsalias")由于历史原因,Oracle dialect 使用过时的 cx_Oracle 驱动程序作为默认 DBAPI
engine = create_engine("oracle://scott:tiger@127.0.0.1:1521/?service_name=freepdb1")
engine = create_engine("oracle+cx_oracle://scott:tiger@tnsalias")有关连接到 Oracle 数据库的更多说明,请访问 Oracle。
Microsoft SQL Server¶
SQL Server dialect 使用 pyodbc 作为默认 DBAPI。pymssql 也可用
# pyodbc
engine = create_engine("mssql+pyodbc://scott:tiger@mydsn")
# pymssql
engine = create_engine("mssql+pymssql://scott:tiger@hostname:port/dbname")有关连接到 SQL Server 的更多说明,请访问 Microsoft SQL Server。
SQLite¶
SQLite 连接到基于文件的数据库,默认情况下使用 Python 内置模块 sqlite3。
由于 SQLite 连接到本地文件,因此 URL 格式略有不同。URL 的 “file” 部分是数据库的文件名。对于相对文件路径,这需要三个斜杠
# sqlite://<nohostname>/<path>
# where <path> is relative:
engine = create_engine("sqlite:///foo.db")对于绝对文件路径,三个斜杠后跟绝对路径
# Unix/Mac - 4 initial slashes in total
engine = create_engine("sqlite:////absolute/path/to/foo.db")
# Windows
engine = create_engine("sqlite:///C:\\path\\to\\foo.db")
# Windows alternative using raw string
engine = create_engine(r"sqlite:///C:\path\to\foo.db")要使用 SQLite :memory: 数据库,请指定一个空 URL
engine = create_engine("sqlite://")有关连接到 SQLite 的更多说明,请访问 SQLite。
其他¶
请参阅 Dialect,所有其他 dialect 文档的顶级页面。
引擎创建 API¶
| 对象名称 | 描述 |
|---|---|
create_engine(url, **kwargs) |
创建一个新的 |
create_mock_engine(url, executor, **kw) |
创建一个用于回显 DDL 的 “模拟” 引擎。 |
create_pool_from_url(url, **kwargs) |
从给定的 URL 创建一个连接池实例。 |
engine_from_config(configuration[, prefix], **kwargs) |
使用配置字典创建一个新的 Engine 实例。 |
make_url(name_or_url) |
给定一个字符串,生成一个新的 URL 实例。 |
表示用于连接到数据库的 URL 的组件。 |
- function sqlalchemy.create_engine(url: str | _url.URL, **kwargs: Any) Engine¶
创建一个新的
Engine实例。标准调用形式是将 URL 作为第一个位置参数发送,通常是一个指示数据库 dialect 和连接参数的字符串
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/test")
注意
请查看 数据库 URL 以获取有关编写 URL 字符串的通用指南。特别是,特殊字符(例如密码中常用的字符)必须进行 URL 编码才能正确解析。
其他关键字参数可以跟随其后,这些参数在生成的
Engine及其底层Dialect和Pool构造上建立各种选项engine = create_engine( "mysql+mysqldb://scott:tiger@hostname/dbname", pool_recycle=3600, echo=True, )
URL 的字符串形式为
dialect[+driver]://user:password@host/dbname[?key=value..],其中dialect是数据库名称,例如mysql、oracle、postgresql等,driver是 DBAPI 的名称,例如psycopg2、pyodbc、cx_oracle等。或者,URL 可以是URL的实例。**kwargs接受各种各样的选项,这些选项被路由到其相应的组件。参数可能是特定于Engine、底层Dialect以及Pool的。特定的 dialect 也接受特定于该 dialect 的关键字参数。在这里,我们描述了大多数create_engine()用法的常用参数。一旦建立,新生成的
Engine将在调用Engine.connect()或调用依赖于它的方法(如Engine.execute())后,从底层Pool请求连接。Pool反过来将在收到此请求时建立第一个实际的 DBAPI 连接。create_engine()调用本身不会直接建立任何实际的 DBAPI 连接。- 参数:
connect_args¶ – 一个选项字典,将作为附加关键字参数直接传递给 DBAPI 的
connect()方法。请参阅 自定义 DBAPI connect() 参数 / 连接时例程 中的示例。creator¶ –
一个可调用对象,返回一个 DBAPI 连接。此创建函数将传递到底层连接池,并将用于创建所有新的数据库连接。使用此函数会导致 URL 参数中指定的连接参数被绕过。
此钩子不如较新的
DialectEvents.do_connect()钩子灵活,后者允许完全控制如何建立与数据库的连接,并预先提供完整的 URL 参数和状态集。echo=False¶ –
如果为 True,则 Engine 将记录所有语句以及其参数列表的
repr()到默认日志处理程序,默认情况下,该处理程序将输出到sys.stdout。如果设置为字符串"debug",则结果行也将打印到标准输出。可以随时修改Engine的echo属性以打开和关闭日志记录;也可以使用标准 Pythonlogging模块直接控制日志记录。另请参阅
配置日志记录 - 有关如何配置日志记录的更多详细信息。
echo_pool=False¶ –
如果为 True,则连接池将记录信息性输出,例如连接何时失效以及连接何时回收,到默认日志处理程序,默认情况下,该处理程序将输出到
sys.stdout。如果设置为字符串"debug",则日志记录将包括池签出和签入。也可以使用标准 Pythonlogging模块直接控制日志记录。另请参阅
配置日志记录 - 有关如何配置日志记录的更多详细信息。
empty_in_strategy¶ –
不再使用;SQLAlchemy 现在在所有情况下都对 IN 使用 “空集” 行为。
自版本 1.4 起已弃用:
create_engine.empty_in_strategy关键字已弃用,并且不再具有任何效果。现在,所有 IN 表达式都使用 “扩展参数” 策略呈现,该策略在语句执行时呈现一组 boundexpression 或 “空集” SELECT。enable_from_linting¶ –
默认为 True。如果发现给定的 SELECT 语句具有未链接的 FROM 元素,这将导致笛卡尔积,则会发出警告。
1.4 版本新增功能。
execution_options¶ – 将应用于所有连接的字典执行选项。请参阅
Connection.execution_options()future¶ –
使用 2.0 样式的
Engine和ConnectionAPI。从 SQLAlchemy 2.0 开始,此参数仅出于向后兼容性而存在,并且必须保持其默认值
True。create_engine.future参数将在后续的 2.x 版本中弃用,并最终删除。1.4 版本新增功能。
在版本 2.0 中更改: 所有
Engine对象都是 “future” 样式引擎,并且不再有future=False操作模式。hide_parameters¶ –
布尔值,设置为 True 时,SQL 语句参数将不会显示在 INFO 日志记录中,也不会格式化为
StatementError对象的字符串表示形式。1.3.8 版本新增功能。
另请参阅
配置日志记录 - 有关如何配置日志记录的更多详细信息。
implicit_returning=True¶ – 只能设置为 True 的旧版参数。在 SQLAlchemy 2.0 中,此参数不起作用。为了禁用 ORM 调用的语句的 “隐式返回”,请使用
Table.implicit_returning参数在每个表的基础上配置此参数。insertmanyvalues_page_size¶ –
当语句使用 “insertmanyvalues” 模式时,要格式化为 INSERT 语句的行数,这是一种批量插入的分页形式,用于许多后端,当使用 executemany 执行时,通常与 RETURNING 结合使用。默认为 1000,但也可能受到特定于 dialect 的限制因素的影响,这些因素可能会在每个语句的基础上覆盖此值。
2.0 版本新增功能。
isolation_level¶ –
可选的字符串,表示隔离级别的名称,该级别将无条件地设置在所有新连接上。隔离级别通常是字符串名称
"SERIALIZABLE","REPEATABLE READ","READ COMMITTED","READ UNCOMMITTED"和"AUTOCOMMIT"的某个子集,具体取决于后端。create_engine.isolation_level参数与Connection.execution_options.isolation_level执行选项形成对比,后者可以设置在单个Connection上,以及传递给Engine.execution_options()的相同参数,后者可用于创建具有不同隔离级别的多个引擎,这些引擎共享一个公共连接池和方言。2.0 版本更改:
create_engine.isolation_level参数已被通用化,可在所有支持隔离级别概念的方言上工作,并且作为更简洁、更直接的配置开关提供,这与执行选项形成对比,后者更像是一种临时的编程选项。json_deserializer¶ –
对于支持
JSON数据类型的方言,这是一个 Python 可调用对象,它将 JSON 字符串转换为 Python 对象。默认情况下,使用 Python 的json.loads函数。1.3.7 版本更改: SQLite 方言将其从
_json_deserializer重命名。json_serializer¶ –
对于支持
JSON数据类型的方言,这是一个 Python 可调用对象,它将给定的对象渲染为 JSON。默认情况下,使用 Python 的json.dumps函数。1.3.7 版本更改: SQLite 方言将其从
_json_serializer重命名。label_length=None¶ –
可选的整数值,用于限制动态生成的列标签的大小为这么多字符。如果小于 6,标签将生成为“_(counter)”。如果为
None,则使用dialect.max_identifier_length的值,该值可能会受到create_engine.max_identifier_length参数的影响。create_engine.label_length的值不得大于create_engine.max_identfier_length的值。logging_name¶ –
字符串标识符,将用于 “sqlalchemy.engine” 日志记录器中生成的日志记录的 “name” 字段。默认为对象 ID 的十六进制字符串。
max_identifier_length¶ –
整数;覆盖由方言确定的 max_identifier_length。如果为
None或零,则无效。这是数据库配置的 SQL 标识符(例如表名、列名或标签名)中可能使用的最大字符数。所有方言都会自动确定此值,但是,如果数据库的新版本更改了此值,但 SQLAlchemy 的方言尚未调整,则可以在此处传递该值。1.3.9 版本新增。
max_overflow=10¶ – 连接池 “溢出” 中允许的连接数,即可以打开的超出 pool_size 设置(默认为 5)的连接数。这仅与
QueuePool一起使用。module=None¶ – 对 Python 模块对象的引用(模块本身,而不是其字符串名称)。指定引擎方言要使用的备用 DBAPI 模块。每个子方言都引用一个特定的 DBAPI,该 DBAPI 将在首次连接之前导入。此参数导致导入被绕过,并使用给定的模块代替。可用于测试 DBAPI 以及将 “mock” DBAPI 实现注入到
Engine中。paramstyle=None¶ – 渲染绑定参数时要使用的 paramstyle。此样式默认为 DBAPI 本身推荐的样式,该样式从 DBAPI 的
.paramstyle属性中检索。但是,大多数 DBAPI 接受多个 paramstyle,特别是可能希望将 “named” paramstyle 更改为 “positional” paramstyle,反之亦然。传递此属性时,它应该是值"qmark","numeric","named","format"或"pyformat"之一,并且应对应于正在使用的 DBAPI 已知的参数样式。pool=None¶ –
Pool的已构造实例,例如QueuePool实例。如果非 None,则此池将直接用作引擎的底层连接池,绕过 URL 参数中存在的任何连接参数。有关手动构建连接池的信息,请参阅 连接池。poolclass=None¶ –
Pool子类,它将用于使用 URL 中给出的连接参数创建连接池实例。请注意,这与pool不同,因为在这种情况下您实际上并没有实例化池,您只是指示要使用的池类型。pool_logging_name¶ –
字符串标识符,将用于 “sqlalchemy.pool” 日志记录器中生成的日志记录的 “name” 字段。默认为对象 ID 的十六进制字符串。
另请参阅
配置日志记录 - 有关如何配置日志记录的更多详细信息。
pool_pre_ping¶ –
布尔值,如果为 True,将启用连接池 “pre-ping” 功能,该功能在每次检出时测试连接的活动性。
1.2 版本新增。
另请参阅
pool_size=5¶ – 连接池中保持打开的连接数。这与
QueuePool以及SingletonThreadPool一起使用。对于QueuePool,pool_size设置为 0 表示没有限制;要禁用池化,请将poolclass设置为NullPool。pool_recycle=-1¶ –
此设置使池在给定的秒数过去后回收连接。它默认为 -1,或无超时。例如,设置为 3600 意味着连接将在一个小时后回收。请注意,特别是 MySQL,如果在连接上检测到八个小时没有活动,将自动断开连接(尽管这可以通过 MySQLDB 连接本身和服务器配置进行配置)。
另请参阅
pool_reset_on_return='rollback'¶ –
设置底层
Pool对象的Pool.reset_on_return参数,该参数可以设置为值"rollback","commit", 或None。另请参阅
pool_timeout=30¶ –
在放弃从池中获取连接之前等待的秒数。这仅与
QueuePool一起使用。这可以是浮点数,但受 Python 时间函数的限制,这些函数在数十毫秒内可能不可靠。pool_use_lifo=False¶ –
从
QueuePool检索连接时,使用 LIFO(后进先出)而不是 FIFO(先进先出)。使用 LIFO,服务器端超时方案可以减少非高峰使用期间使用的连接数。在规划服务器端超时时,请确保使用回收或 pre-ping 策略来优雅地处理过时的连接。1.3 版本新增。
plugins¶ –
要加载的插件名称的字符串列表。有关背景信息,请参阅
CreateEnginePlugin。1.2.3 版本新增。
query_cache_size¶ –
用于缓存查询的 SQL 字符串形式的缓存大小。设置为零以禁用缓存。
当缓存大小达到 N * 1.5 时,缓存会修剪最近最少使用的项目。默认为 500,这意味着缓存始终会在填充时存储至少 500 个 SQL 语句,并且最多增长到 750 个项目,此时通过删除 250 个最近最少使用的项目将其修剪回 500 个。
缓存是基于每个语句完成的,方法是生成一个表示语句结构的缓存键,然后仅当该键不存在于缓存中时才为当前方言生成字符串 SQL。所有语句都支持缓存,但是某些功能(例如带有大量参数的 INSERT)将有意绕过缓存。SQL 日志记录将指示每个语句的统计信息,无论它是否从缓存中拉取。
注意
一些与工作单元持久性相关的 ORM 函数以及一些属性加载策略将使用主缓存之外的各个 per-mapper 缓存。
另请参阅
1.4 版本新增功能。
use_insertmanyvalues¶ –
默认为 True,默认情况下对 INSERT..RETURNING 语句使用 “insertmanyvalues” 执行样式。
2.0 版本新增功能。
- function sqlalchemy.engine_from_config(configuration: Dict[str, Any], prefix: str = 'sqlalchemy.', **kwargs: Any) Engine¶
使用配置字典创建一个新的 Engine 实例。
该字典通常从配置文件生成。
engine_from_config()感兴趣的键应带有前缀,例如sqlalchemy.url,sqlalchemy.echo, 等。“prefix” 参数指示要搜索的前缀。每个匹配的键(在剥离前缀后)都被视为它是对create_engine()调用的相应关键字参数。唯一必需的键是(假设默认前缀)
sqlalchemy.url,它提供 数据库 URL。一小组关键字参数将基于字符串值 “强制转换” 为其预期类型。参数集可以使用
engine_config_types访问器按方言扩展。- 参数:
configuration¶ – 一个字典(通常从配置文件生成,但这并非必要条件)。键以 ‘prefix’ 值开头的项将剥离该前缀,然后传递给
create_engine()。prefix¶ – 要匹配的前缀,然后从 ‘configuration’ 中的键中剥离。
kwargs¶ –
engine_from_config()本身的每个关键字参数都会覆盖从 ‘configuration’ 字典中获取的相应项。关键字参数不应带有前缀。
- function sqlalchemy.create_mock_engine(url: str | URL, executor: Any, **kw: Any) MockConnection¶
创建一个用于回显 DDL 的 “模拟” 引擎。
这是一个实用程序函数,用于调试或存储由
MetaData.create_all()和相关方法生成的 DDL 序列的输出。该函数接受一个 URL,该 URL 仅用于确定要使用的方言类型,以及一个 “executor” 可调用函数,该函数将接收 SQL 表达式对象和参数,然后可以回显或以其他方式打印。执行器的返回值不被处理,引擎也不允许调用常规字符串语句,因此仅对发送到数据库而不接收任何结果的 DDL 有用。
例如
from sqlalchemy import create_mock_engine def dump(sql, *multiparams, **params): print(sql.compile(dialect=engine.dialect)) engine = create_mock_engine("postgresql+psycopg2://", dump) metadata.create_all(engine, checkfirst=False)
- 参数:
url¶ – 一个字符串 URL,通常只需要包含数据库后端名称。
executor¶ – 一个可调用对象,它接收参数
sql,*multiparams和**params。sql参数通常是ExecutableDDLElement的实例,然后可以使用ExecutableDDLElement.compile()将其编译为字符串。
1.4 版本新增: -
create_mock_engine()函数取代了以前与create_engine()一起使用的 “mock” 引擎策略。
- function sqlalchemy.engine.make_url(name_or_url: str | URL) URL¶
给定一个字符串,生成一个新的 URL 实例。
URL 的格式通常遵循 RFC-1738,但有一些例外,包括在 “scheme” 部分中接受下划线,而不是短划线或句点。
如果传递了
URL对象,则按原样返回。另请参阅
- function sqlalchemy.create_pool_from_url(url: str | URL, **kwargs: Any) Pool¶
从给定的 URL 创建一个连接池实例。
如果未提供
poolclass,则使用的池类是使用 URL 中指定的方言选择的。传递给
create_pool_from_url()的参数与传递给create_engine()函数的 pool 参数相同。2.0.10 版本新增。
- class sqlalchemy.engine.URL¶
表示用于连接到数据库的 URL 的组件。
URL 通常从完全格式化的 URL 字符串构造,其中
make_url()函数由create_engine()函数在内部使用,以便将 URL 字符串解析为其各个组件,然后这些组件用于构造新的URL对象。从格式化的 URL 字符串解析时,解析格式通常遵循 RFC-1738,但有一些例外。URL对象也可以直接生成,可以通过使用带有完全格式化的 URL 字符串的make_url()函数,或者通过使用URL.create()构造函数来以编程方式构造URL,给定各个字段。生成的URL对象可以直接传递给create_engine()以代替字符串参数,这将绕过在引擎创建过程中使用make_url()。1.4 版本更改:
URL对象现在是不可变对象。要创建 URL,请使用make_url()或URL.create()函数/方法。要修改URL,请使用URL.set()和URL.update_query_dict()等方法返回带有修改的新URL对象。有关此更改的注释,请参阅 The URL object is now immutable。另请参阅
URL包含以下属性URL.drivername: 数据库后端和驱动程序名称,例如postgresql+psycopg2URL.username: 用户名字符串URL.password: 密码字符串URL.host: 字符串主机名URL.port: 整数端口号URL.database: 字符串数据库名称URL.query: 表示查询字符串的不可变映射。包含字符串作为键,以及字符串或字符串元组作为值。
成员
create(), database, difference_update_query(), drivername, get_backend_name(), get_dialect(), get_driver_name(), host, normalized_query, password, port, query, render_as_string(), set(), translate_connect_args(), update_query_dict(), update_query_pairs(), update_query_string(), username
类签名
class
sqlalchemy.engine.URL(builtins.tuple)-
classmethod
sqlalchemy.engine.URL.create(drivername: str, username: str | None = None, password: str | None = None, host: str | None = None, port: int | None = None, database: str | None = None, query: Mapping[str, Sequence[str] | str] = {}) URL¶ 创建新的
URL对象。另请参阅
- 参数:
drivername¶ – 数据库后端名称。此名称将对应于 sqlalchemy/databases 中的模块或第三方插件。
username¶ – 用户名。
password¶ –
数据库密码。通常是字符串,但也可能是可以使用
str()字符串化的对象。注意
当作为参数传递给
URL.create()时,密码字符串不应进行 URL 编码;该字符串应包含密码字符,就像它们被键入时一样。注意
每个
Engine对象,密码生成对象仅字符串化一次。 对于每次连接的动态密码生成,请参阅 生成动态身份验证令牌。host¶ – 主机名。
port¶ – 端口号。
database¶ – 数据库名称。
query¶ – 字符串键到字符串值的字典,用于在连接时传递给 dialect 和/或 DBAPI。要直接向 Python DBAPI 指定非字符串参数,请使用
create_engine.connect_args参数到create_engine()。另请参阅URL.normalized_query以获取一致的 string->string 列表的字典。
- 返回:
新的
URL对象。
1.4 版本新增:
URL对象现在是一个不可变的命名元组。 此外,query字典也是不可变的。 要创建 URL,请使用make_url()或URL.create()函数/方法。 要修改URL,请使用URL.set()和URL.update_query()方法。
-
attribute
sqlalchemy.engine.URL.database: str | None¶ 数据库名称
-
method
sqlalchemy.engine.URL.difference_update_query(names: Iterable[str]) URL¶ 从
URL.query字典中删除给定的名称,并返回新的URL。例如
url = url.difference_update_query(["foo", "bar"])
等效于使用
URL.set()如下所示url = url.set( query={ key: url.query[key] for key in set(url.query).difference(["foo", "bar"]) } )
1.4 版本新增功能。
-
attribute
sqlalchemy.engine.URL.drivername: str¶ 数据库后端和驱动程序名称,例如
postgresql+psycopg2
-
method
sqlalchemy.engine.URL.get_backend_name() str¶ 返回后端名称。
这是与正在使用的数据库后端相对应的名称,并且是
URL.drivername中加号左侧的部分。
-
method
sqlalchemy.engine.URL.get_dialect(_is_async: bool = False) Type[Dialect]¶ 返回与此 URL 的驱动程序名称对应的 SQLAlchemy
Dialect类。
-
method
sqlalchemy.engine.URL.get_driver_name() str¶ 返回后端名称。
这是与正在使用的 DBAPI 驱动程序相对应的名称,并且是
URL.drivername中加号右侧的部分。如果
URL.drivername不包含加号,则导入此URL的默认Dialect以获取驱动程序名称。
-
attribute
sqlalchemy.engine.URL.host: str | None¶ 主机名或 IP 号。 对于某些驱动程序,也可能是数据源名称。
-
attribute
sqlalchemy.engine.URL.normalized_query¶ 返回
URL.query字典,其值已标准化为序列。由于
URL.query字典可能包含字符串值或字符串值序列,以区分在查询字符串中多次指定的参数,因此需要通用处理多个参数的代码将希望使用此属性,以便将所有存在的参数都表示为序列。灵感来自 Python 的urllib.parse.parse_qs函数。 例如>>> from sqlalchemy.engine import make_url >>> url = make_url( ... "postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt" ... ) >>> url.query immutabledict({'alt_host': ('host1', 'host2'), 'ssl_cipher': '/path/to/crt'}) >>> url.normalized_query immutabledict({'alt_host': ('host1', 'host2'), 'ssl_cipher': ('/path/to/crt',)})
-
attribute
sqlalchemy.engine.URL.password: str | None¶ 密码,通常是字符串,但也可能是任何具有
__str__()方法的对象。
-
attribute
sqlalchemy.engine.URL.port: int | None¶ 整数端口号
-
attribute
sqlalchemy.engine.URL.query: immutabledict[str, Tuple[str, ...] | str]¶ 表示查询字符串的不可变映射。 包含字符串键以及字符串或字符串元组的值,例如
>>> from sqlalchemy.engine import make_url >>> url = make_url( ... "postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt" ... ) >>> url.query immutabledict({'alt_host': ('host1', 'host2'), 'ssl_cipher': '/path/to/crt'}) To create a mutable copy of this mapping, use the ``dict`` constructor:: mutable_query_opts = dict(url.query)
-
method
sqlalchemy.engine.URL.render_as_string(hide_password: bool = True) str¶ 将此
URL对象呈现为字符串。当使用
__str__()或__repr__()方法时,将使用此方法。 该方法直接包含其他选项。- 参数:
hide_password¶ – 默认为 True。除非设置为 False,否则密码不会显示在字符串中。
-
method
sqlalchemy.engine.URL.set(drivername: str | None = None, username: str | None = None, password: str | None = None, host: str | None = None, port: int | None = None, database: str | None = None, query: Mapping[str, Sequence[str] | str] | None = None) URL¶ 返回使用修改后的新的
URL对象。如果值不是 None,则使用这些值。 要将值显式设置为
None,请使用从namedtuple改编的URL._replace()方法。- 参数:
- 返回:
新的
URL对象。
1.4 版本新增功能。
-
method
sqlalchemy.engine.URL.translate_connect_args(names: List[str] | None = None, **kw: Any) Dict[str, Any]¶ 将 url 属性转换为连接参数字典。
将此 url 的属性(host、database、username、password、port)作为纯字典返回。 默认情况下,属性名称用作键。 未设置或 false 的属性将从最终字典中省略。
-
method
sqlalchemy.engine.URL.update_query_dict(query_parameters: Mapping[str, str | List[str]], append: bool = False) URL¶ 返回新的
URL对象,其中URL.query参数字典已通过给定的字典更新。该字典通常包含字符串键和字符串值。 为了表示多次表达的查询参数,请传递字符串值序列。
例如
>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname") >>> url = url.update_query_dict( ... {"alt_host": ["host1", "host2"], "ssl_cipher": "/path/to/crt"} ... ) >>> str(url) 'postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt'
- 参数:
1.4 版本新增功能。
-
method
sqlalchemy.engine.URL.update_query_pairs(key_value_pairs: Iterable[Tuple[str, str | List[str]]], append: bool = False) URL¶ 返回新的
URL对象,其中URL.query参数字典已通过给定的键/值对序列更新例如
>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname") >>> url = url.update_query_pairs( ... [ ... ("alt_host", "host1"), ... ("alt_host", "host2"), ... ("ssl_cipher", "/path/to/crt"), ... ] ... ) >>> str(url) 'postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt'
- 参数:
1.4 版本新增功能。
-
method
sqlalchemy.engine.URL.update_query_string(query_string: str, append: bool = False) URL¶ 返回新的
URL对象,其中URL.query参数字典已通过给定的查询字符串更新。例如
>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname") >>> url = url.update_query_string( ... "alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt" ... ) >>> str(url) 'postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt'
- 参数:
1.4 版本新增功能。
-
attribute
sqlalchemy.engine.URL.username: str | None¶ 用户名字符串
连接池¶
当调用 connect() 或 execute() 方法时,Engine 将向连接池请求连接。 默认连接池 QueuePool 将根据需要打开与数据库的连接。 当并发语句执行时,QueuePool 将将其连接池扩展到默认大小 5,并允许默认的“溢出” 10。 由于 Engine 本质上是连接池的“基地”,因此您应该在应用程序中为每个已建立的数据库保留一个 Engine,而不是为每个连接创建一个新的引擎。
有关连接池的更多信息,请参阅 连接池。
自定义 DBAPI connect() 参数 / 连接时例程¶
对于需要特殊连接方法的情况,在绝大多数情况下,最适合在 create_engine() 级别使用几种钩子之一来自定义此过程。 这些将在以下小节中描述。
传递给 dbapi.connect() 的特殊关键字参数¶
所有 Python DBAPI 都接受超出基本连接的其他参数。 常用参数包括用于指定字符集编码和超时值的参数; 更复杂的数据包括特殊的 DBAPI 常量和对象以及 SSL 子参数。 有两种基本方法可以在不增加复杂性的情况下传递这些参数。
将参数添加到 URL 查询字符串¶
简单的字符串值,以及一些数值和布尔标志,通常可以直接在 URL 的查询字符串中指定。 一个常见的例子是 DBAPI 接受用于字符集编码的 encoding 参数,例如大多数 MySQL DBAPI
engine = create_engine("mysql+pymysql://user:pass@host/test?charset=utf8mb4")使用查询字符串的优点是,可以在配置文件中以可移植到 URL 中指定的 DBAPI 的方式指定其他 DBAPI 选项。 在此级别传递的特定参数因 SQLAlchemy 方言而异。 一些方言将所有参数作为字符串传递,而另一些方言将解析特定数据类型并将参数移动到不同的位置,例如驱动程序级别的 DSN 和连接字符串中。 由于此区域的每种方言行为目前各不相同,因此应查阅正在使用的特定方言的方言文档,以查看在此级别是否支持特定参数。
提示
显示传递给给定 URL 的 DBAPI 的确切参数的一种通用技术是直接使用 Dialect.create_connect_args() 方法,如下所示
>>> from sqlalchemy import create_engine
>>> engine = create_engine(
... "mysql+pymysql://some_user:some_pass@some_host/test?charset=utf8mb4"
... )
>>> args, kwargs = engine.dialect.create_connect_args(engine.url)
>>> args, kwargs
([], {'host': 'some_host', 'database': 'test', 'user': 'some_user', 'password': 'some_pass', 'charset': 'utf8mb4', 'client_flag': 2})上面的 args, kwargs 对通常作为 dbapi.connect(*args, **kwargs) 传递给 DBAPI。
使用 connect_args 字典参数¶
一种更通用的系统,用于将任何参数传递给保证始终传递所有参数的 dbapi.connect() 函数,是 create_engine.connect_args 字典参数。 这可以用于方言在添加到查询字符串时未以其他方式处理的参数,以及必须将特殊子结构或对象传递给 DBAPI 时。 有时只是必须将特定标志作为 True 符号发送,而 SQLAlchemy 方言不知道此关键字参数以将其从 URL 中呈现的字符串形式强制转换。 下面说明了 psycopg2 “连接工厂” 的用法,该工厂替换了连接的底层实现
engine = create_engine(
"postgresql+psycopg2://user:pass@hostname/dbname",
connect_args={"connection_factory": MyConnectionFactory},
)另一个示例是 pyodbc “timeout” 参数
engine = create_engine(
"mssql+pyodbc://user:pass@sqlsrvr?driver=ODBC+Driver+13+for+SQL+Server",
connect_args={"timeout": 30},
)上面的示例还说明了 URL “查询字符串” 参数和 create_engine.connect_args 可以同时使用; 对于 pyodbc, “driver” 关键字在 URL 中具有特殊含义。
控制参数如何传递给 DBAPI connect() 函数¶
除了操作传递给 connect() 的参数之外,我们还可以进一步自定义 DBAPI connect() 函数本身的调用方式,使用 DialectEvents.do_connect() 事件钩子。 此钩子传递方言将发送到 connect() 的完整 *args, **kwargs。 然后可以就地修改这些集合,以更改它们的使用方式
from sqlalchemy import event
engine = create_engine("postgresql+psycopg2://user:pass@hostname/dbname")
@event.listens_for(engine, "do_connect")
def receive_do_connect(dialect, conn_rec, cargs, cparams):
cparams["connection_factory"] = MyConnectionFactory生成动态身份验证令牌¶
DialectEvents.do_connect() 也是动态插入身份验证令牌的理想方法,该令牌可能会在 Engine 的生命周期内发生变化。 例如,如果令牌由 get_authentication_token() 生成,并在 token 参数中传递给 DBAPI,则可以按如下方式实现
from sqlalchemy import event
engine = create_engine("postgresql+psycopg2://user@hostname/dbname")
@event.listens_for(engine, "do_connect")
def provide_token(dialect, conn_rec, cargs, cparams):
cparams["token"] = get_authentication_token()另请参阅
使用访问令牌连接到数据库 - 一个更具体的示例,涉及 SQL Server
在连接后修改 DBAPI 连接,或在连接后运行命令¶
对于 SQLAlchemy 创建的没有问题的 DBAPI 连接,但我们希望在实际使用之前修改已完成的连接,例如设置特殊标志或运行某些命令,PoolEvents.connect() 事件钩子是最合适的钩子。 对于创建的每个新连接,都会调用此钩子,在 SQLAlchemy 使用它之前
from sqlalchemy import event
engine = create_engine("postgresql+psycopg2://user:pass@hostname/dbname")
@event.listens_for(engine, "connect")
def connect(dbapi_connection, connection_record):
cursor_obj = dbapi_connection.cursor()
cursor_obj.execute("SET some session variables")
cursor_obj.close()完全替换 DBAPI connect() 函数¶
最后,DialectEvents.do_connect() 事件钩子还允许我们完全接管连接过程,方法是建立连接并返回它
from sqlalchemy import event
engine = create_engine("postgresql+psycopg2://user:pass@hostname/dbname")
@event.listens_for(engine, "do_connect")
def receive_do_connect(dialect, conn_rec, cargs, cparams):
# return the new DBAPI connection with whatever we'd like to
# do
return psycopg2.connect(*cargs, **cparams)DialectEvents.do_connect() 钩子取代了之前的 create_engine.creator 钩子,该钩子仍然可用。 DialectEvents.do_connect() 具有明显的优势,即从 URL 解析的完整参数也传递给用户定义的函数,而 create_engine.creator 则不然。
配置日志记录¶
Python 的标准 logging 模块用于实现 SQLAlchemy 的信息性和调试日志输出。 这允许 SQLAlchemy 的日志记录以标准方式与其他应用程序和库集成。 create_engine() 上还存在两个参数 create_engine.echo 和 create_engine.echo_pool,它们允许立即记录到 sys.stdout 以用于本地开发; 这些参数最终与下面描述的常规 Python 记录器交互。
本节假定您熟悉上面链接的 logging 模块。 SQLAlchemy 执行的所有日志记录都存在于 sqlalchemy 命名空间下,如 logging.getLogger('sqlalchemy') 所用。 当日志记录已配置(例如,通过 logging.basicConfig())时,可以打开的 SA 记录器的通用命名空间如下
sqlalchemy.engine- 控制 SQL 回显。 设置为logging.INFO以输出 SQL 查询,设置为logging.DEBUG以输出查询 + 结果集。 这些设置分别等效于create_engine.echo上的echo=True和echo="debug"。sqlalchemy.pool- 控制连接池日志记录。 设置为logging.INFO以记录连接失效和回收事件; 设置为logging.DEBUG以另外记录所有池检入和检出。 这些设置分别等效于create_engine.echo_pool上的pool_echo=True和pool_echo="debug"。sqlalchemy.dialects- 控制 SQL 方言的自定义日志记录,在特定方言中使用日志记录的范围内,通常是最小的。sqlalchemy.orm- 控制各种 ORM 功能的日志记录,在 ORM 中使用日志记录的范围内,通常是最小的。 设置为logging.INFO以记录有关映射器配置的一些顶级信息。
例如,要使用 Python 日志记录而不是 echo=True 标志来记录 SQL 查询
import logging
logging.basicConfig()
logging.getLogger("sqlalchemy.engine").setLevel(logging.INFO)默认情况下,日志级别在整个 sqlalchemy 命名空间内设置为 logging.WARN,以便即使在已启用日志记录的应用程序中也不会发生日志操作。
注意
SQLAlchemy Engine 通过仅在检测到当前日志记录级别为 logging.INFO 或 logging.DEBUG 时才发出日志语句来节省 Python 函数调用开销。 它仅在从连接池获取新连接时才检查此级别。 因此,当更改已运行应用程序的日志记录配置时,任何当前处于活动状态的 Connection,或者更常见的是在事务中处于活动状态的 Session 对象,在新 Connection 被获取之前(在 Session 的情况下,这在当前事务结束且新事务开始之后)不会根据新配置记录任何 SQL。
关于 Echo 标志的更多信息¶
如前所述,create_engine.echo 和 create_engine.echo_pool 参数是立即记录到 sys.stdout 的快捷方式
>>> from sqlalchemy import create_engine, text
>>> e = create_engine("sqlite://", echo=True, echo_pool="debug")
>>> with e.connect() as conn:
... print(conn.scalar(text("select 'hi'")))
2020-10-24 12:54:57,701 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Created new connection <sqlite3.Connection object at 0x7f287819ac60>
2020-10-24 12:54:57,701 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Connection <sqlite3.Connection object at 0x7f287819ac60> checked out from pool
2020-10-24 12:54:57,702 INFO sqlalchemy.engine.Engine select 'hi'
2020-10-24 12:54:57,702 INFO sqlalchemy.engine.Engine ()
hi
2020-10-24 12:54:57,703 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Connection <sqlite3.Connection object at 0x7f287819ac60> being returned to pool
2020-10-24 12:54:57,704 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Connection <sqlite3.Connection object at 0x7f287819ac60> rollback-on-return使用这些标志大致等效于
import logging
logging.basicConfig()
logging.getLogger("sqlalchemy.engine").setLevel(logging.INFO)
logging.getLogger("sqlalchemy.pool").setLevel(logging.DEBUG)重要的是要注意,这两个标志与任何现有的日志记录配置独立工作,并将无条件地使用 logging.basicConfig()。 这具有除了任何现有记录器配置之外还进行配置的效果。 因此,在显式配置日志记录时,请确保始终将所有 echo 标志设置为 False,以避免获得重复的日志行。
设置日志记录名称¶
Engine 或 Pool 的记录器名称设置为对象的模块限定类名。 可以使用 create_engine.logging_name 和 create_engine.pool_logging_name 参数以及 sqlalchemy.create_engine() 进一步限定此名称; 该名称将附加到现有的类限定日志记录名称。 建议同时使用多个全局 Engine 实例的应用程序使用此功能,以便可以在日志记录中区分它们
>>> import logging
>>> from sqlalchemy import create_engine
>>> from sqlalchemy import text
>>> logging.basicConfig()
>>> logging.getLogger("sqlalchemy.engine.Engine.myengine").setLevel(logging.INFO)
>>> e = create_engine("sqlite://", logging_name="myengine")
>>> with e.connect() as conn:
... conn.execute(text("select 'hi'"))
2020-10-24 12:47:04,291 INFO sqlalchemy.engine.Engine.myengine select 'hi'
2020-10-24 12:47:04,292 INFO sqlalchemy.engine.Engine.myengine ()提示
create_engine.logging_name 和 create_engine.pool_logging_name 参数也可以与 create_engine.echo 和 create_engine.echo_pool 结合使用。 但是,如果使用 echo 标志设置为 True 且没有日志记录名称创建其他引擎,则会发生不可避免的双重日志记录情况。 这是因为将自动为 sqlalchemy.engine.Engine 添加一个处理程序,该处理程序将记录无名称引擎以及具有日志记录名称的引擎的消息。 例如
from sqlalchemy import create_engine, text
e1 = create_engine("sqlite://", echo=True, logging_name="myname")
with e1.begin() as conn:
conn.execute(text("SELECT 1"))
e2 = create_engine("sqlite://", echo=True)
with e2.begin() as conn:
conn.execute(text("SELECT 2"))
with e1.begin() as conn:
conn.execute(text("SELECT 3"))上面的场景将双重记录 SELECT 3。 要解决此问题,请确保所有引擎都设置了 logging_name,或者使用显式记录器/处理程序设置,而不使用 create_engine.echo 和 create_engine.echo_pool。
设置每个连接/子引擎令牌¶
1.4.0b2 版本新增功能。
虽然日志记录名称适合在长期存在的 Engine 对象上建立,但它不够灵活,无法适应任意大的名称列表,以用于跟踪日志消息中的各个连接和/或事务。
对于这种情况,Connection 和 Result 对象生成的日志消息本身可以使用其他令牌进行扩充,例如事务或请求标识符。 Connection.execution_options.logging_token 参数接受一个字符串参数,该参数可用于建立每个连接的跟踪令牌
>>> from sqlalchemy import create_engine
>>> e = create_engine("sqlite://", echo="debug")
>>> with e.connect().execution_options(logging_token="track1") as conn:
... conn.execute(text("select 1")).all()
2021-02-03 11:48:45,754 INFO sqlalchemy.engine.Engine [track1] select 1
2021-02-03 11:48:45,754 INFO sqlalchemy.engine.Engine [track1] [raw sql] ()
2021-02-03 11:48:45,754 DEBUG sqlalchemy.engine.Engine [track1] Col ('1',)
2021-02-03 11:48:45,755 DEBUG sqlalchemy.engine.Engine [track1] Row (1,)Connection.execution_options.logging_token 参数也可以通过 create_engine.execution_options 或 Engine.execution_options() 在引擎或子引擎上建立。 这可能有助于将不同的日志记录令牌应用于应用程序的不同组件,而无需创建新引擎
>>> from sqlalchemy import create_engine
>>> e = create_engine("sqlite://", echo="debug")
>>> e1 = e.execution_options(logging_token="track1")
>>> e2 = e.execution_options(logging_token="track2")
>>> with e1.connect() as conn:
... conn.execute(text("select 1")).all()
2021-02-03 11:51:08,960 INFO sqlalchemy.engine.Engine [track1] select 1
2021-02-03 11:51:08,960 INFO sqlalchemy.engine.Engine [track1] [raw sql] ()
2021-02-03 11:51:08,960 DEBUG sqlalchemy.engine.Engine [track1] Col ('1',)
2021-02-03 11:51:08,961 DEBUG sqlalchemy.engine.Engine [track1] Row (1,)
>>> with e2.connect() as conn:
... conn.execute(text("select 2")).all()
2021-02-03 11:52:05,518 INFO sqlalchemy.engine.Engine [track2] Select 1
2021-02-03 11:52:05,519 INFO sqlalchemy.engine.Engine [track2] [raw sql] ()
2021-02-03 11:52:05,520 DEBUG sqlalchemy.engine.Engine [track2] Col ('1',)
2021-02-03 11:52:05,520 DEBUG sqlalchemy.engine.Engine [track2] Row (1,)隐藏参数¶
Engine 发出的日志记录还指示特定语句存在的 SQL 参数的摘录。 为了防止出于隐私目的记录这些参数,请启用 create_engine.hide_parameters 标志
>>> e = create_engine("sqlite://", echo=True, hide_parameters=True)
>>> with e.connect() as conn:
... conn.execute(text("select :some_private_name"), {"some_private_name": "pii"})
2020-10-24 12:48:32,808 INFO sqlalchemy.engine.Engine select ?
2020-10-24 12:48:32,808 INFO sqlalchemy.engine.Engine [SQL parameters hidden due to hide_parameters=True]